AI SEO Platform
Our AI SEO Platform: 6 Specialist Flows for SEO Audits, Backlinks, SERP Analysis, Content Briefs and GSC Reports
- Jump to section:
- The 6 specialist agents (each one solves one SEO job)
- The opinionated playbook ClientCues runs by default
- Credits, not subscriptions: how we make AI cost transparent
- The self-rotating recommendation loop that keeps the content fresh
- Why an AI SEO platform built on multi-agent orchestration beats a single ChatGPT SEO prompt
- How this compares to other AI SEO tools, SEO automation software, and competitor analysis tools
- What is next: self-hosted Google Search Console
- Try it: run the AI SEO platform on your own site
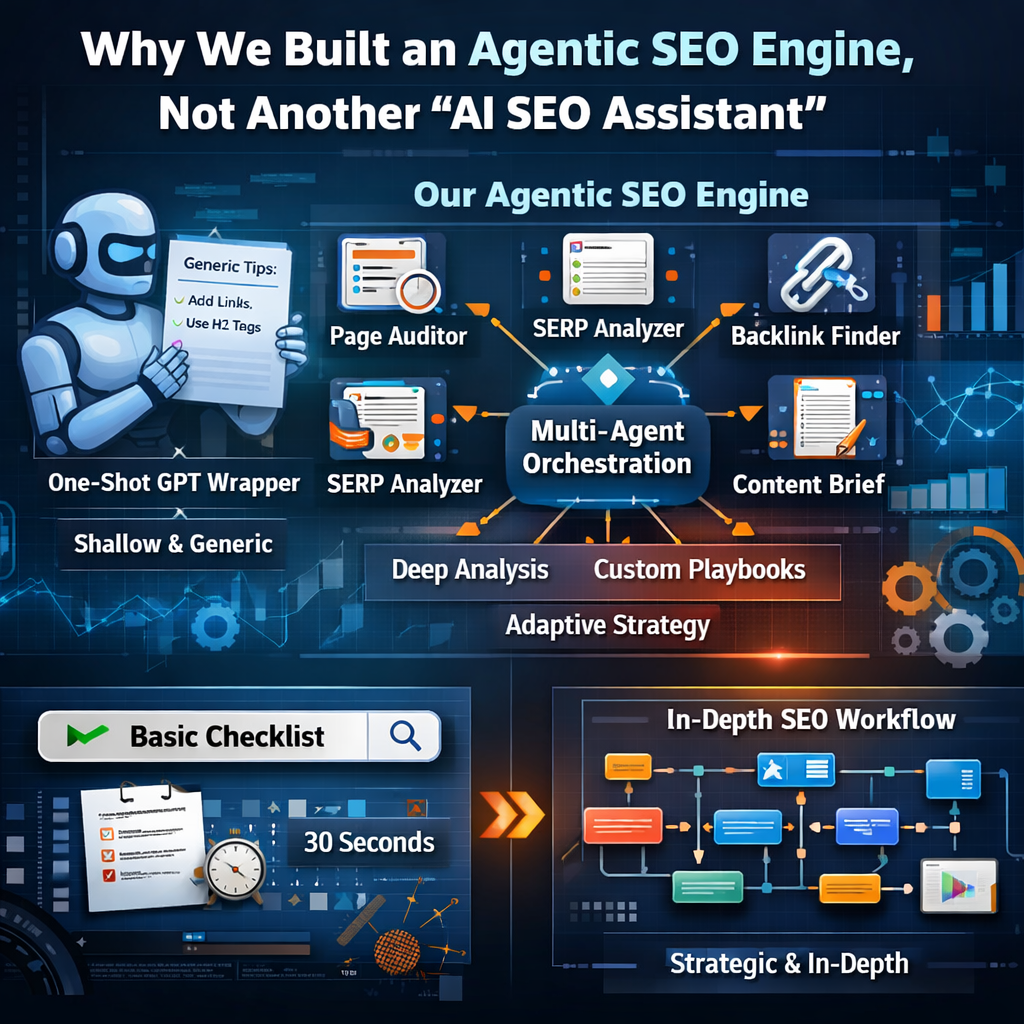
Why we built an AI SEO platform on multi-agent orchestration instead of another "AI SEO assistant"
Most AI SEO tools are one-shot ChatGPT wrappers. You paste a URL, the tool fires a single prompt to GPT-4, and 30 seconds later you get a generic checklist: add more internal links, increase word count, use H2 tags. The advice is shallow, and the tool has no memory of what it recommended last week. We built ClientCues to solve a different problem: how do you give a 10-person startup the same depth of SEO automation and competitor analysis that enterprise teams get from $30K/year platforms? The answer turned out to be multi-agent orchestration, not bigger prompts. This post walks through the AI SEO platform we ended up with: 6 specialist Evaligo flows that handle the SEO audit, backlinks checker, SERP analysis, content brief, keyword competitor insights, and Google Search Console reporting jobs, an opinionated playbook orchestrator, a credit-gated ledger, and a weekly picker agent that keeps our comparison content fresh by reading live web signals instead of a static editorial calendar.
The 6 specialist agents (each one solves one SEO job)
Every Evaligo flow we ship is a small agent, not a giant prompt. Each has a fixed credit cost, a runtime budget, and a clear input/output contract. Here is the full roster:
| Flow | Cost | Runtime | Input | Key Output | Internals | |
|---|---|---|---|---|---|---|
| SEO Page Auditor | 5 credits | 30-60s | { url } | overallSeoScore (0-100), priorityActions, per-recommendation {category, issueSeverity, currentState, recommendedAction, expectedImpact} | fetchHtml → extract signals → generate recommendations (3 nodes) | |
| SERP Content Analyzer | 12 credits | 3-5 min | { keyword } | top_results, title_patterns, avg_word_count, common_topics, content_angles, semantic_keywords, content_gaps | googleSearch → iterator → fetchHtml per result → htmlTextExtractor → analysis prompt (10 parallel fetches) | |
| Backlink Opportunity Finder | 12 credits | 3-5 min | { domain } | backlink_opportunities array (url, domain, opportunity_type, niche_relevance, outreach_suggestion), summary | Single agentic LLM with google_search + fetch_page_content tools, 15-iteration cap | |
| Content Brief Generator | 20 credits | 5-8 min | { target_keyword, website_url } | title_h1, meta_description, heading_structure, target_word_count, questions_to_answer, key_topics, internal_linking, unique_angle, seo_keywords, writing_tips | SERP search → top-10 fetch → structure extraction → 50-page parallel crawler → internal-link analysis → brief generation (6 chained agents) | |
| Keyword Performance Insights | 15 credits | 3-7 min | { keyword, domain } | current_ranking, top_competitors with why_they_rank_better, serp_features, click_appeal_analysis, backlink_insights, content_gaps, search_intent, prioritized recommendations | Single agentic LLM with google_search + fetch_page_content + crawl_webpage tools, 20-iteration cap | |
| GSC Performance Reporter | 8 credits | 1-2 min | { site_url, date_range } | report_markdown, typed arrays for top_queries, top_pages, quick_wins, low_hanging_fruit, recommendations | Runs against Google Search Console via Evaligo connectionId (Phase 3 self-hosts OAuth) |
SEO Page Auditor — automated SEO audit in 30 seconds (flow id b249751a-c9a2-42a9-a9b8-63077fcaee39). The auditor is the cheapest flow at 5 credits and the fastest at 30 to 60 seconds. You pass a URL, it returns an overall SEO score from 0 to 100 plus a prioritized action list — the same surface you would expect from any seo audit tool, but produced by an agent. Each recommendation includes the issue category, severity level, current state, recommended action, and expected impact. Under the hood it is three nodes: fetch the HTML, extract SEO signals (title, meta, headers, alt tags, schema), and generate recommendations. This is the diagnostic you run first on a new site or before publishing new pages.
SERP Content Analyzer — SERP analysis tool for any keyword (flow id 914340ff-08d9-48d6-a8e3-e2fe093b1373). The SERP analyzer is where the agentic architecture pays off. For 12 credits and 3 to 5 minutes, you get the richest single-keyword SERP intelligence structure we have, comparable to what dedicated serp tools or rank tracking tools surface but generated end-to-end by an agent. It searches Google for your keyword, fetches the top 10 results in parallel, extracts the HTML from each, and runs an analysis prompt over the combined data. The output includes title patterns (common formats, average length, power words), an average word count target, common topics with subtopics and heading structures, content angles ranked by frequency, semantic keywords (entities, recurring phrases, LSI terms), and content gaps tagged with opportunity levels. That iterator over 10 pages is the agentic part. A single LLM call cannot do this.
Backlink Opportunity Finder — an agentic backlinks checker and competitor backlink analysis (flow id e7bba816-385c-41a3-8c5a-b932d9e3f532). The backlink finder costs 12 credits and runs for 3 to 5 minutes. You pass a domain, it returns an array of backlink opportunities with the URL, owning domain, opportunity type, niche relevance score, and an outreach suggestion — combining what a traditional backlinks checker and a competitor backlink analysis tool would each do, but in a single agent run. This flow is a single agentic LLM with two tools: google_search and fetch_page_content. It is capped at 15 iterations. The agent decides when to stop searching. There is no fixed graph. This is the difference between a static prompt and an agent that explores.
Content Brief Generator — multi-page content brief from one keyword (flow id 14e11505-c6fe-4214-8ae9-dfb643a9146c). The content brief generator is the most expensive flow at 20 credits and the longest at 5 to 8 minutes. It is also the most complete. You pass a target keyword and your website URL. The flow searches the SERP, iterates over the top 10 results, fetches the HTML from each, extracts the heading structure, then runs a parallel crawler against your site (depth 2, up to 50 pages) to analyze your internal link structure. The output is a full content brief — title and H1, meta description, heading structure with H2/H3 nesting, target word count, questions to answer, key topics, internal linking suggestions with target URLs and anchor text, a unique angle, content depth guidance, SEO keywords split into primary, secondary and LSI, plus writing tips. That is six agents chained together. You cannot get this from a single prompt, and you cannot get it as a one-line content brief generator API call from any of the major ai seo tools today.
Keyword Performance Insights — competitor analysis tool for any keyword (flow id 1fdbe58a-45de-43b6-8b08-ed420d27849f). The keyword performance flow costs 15 credits and runs for 3 to 7 minutes. This is the "why am I not ranking for X?" diagnostic, and the closest the platform gets to a traditional competitor analysis tool focused on a single search. You pass a keyword and your domain. The flow returns your current ranking, a list of top competitors with explanations of why they rank better, SERP features (featured snippet, People Also Ask, knowledge panel, rich results), click appeal analysis (title issues, meta description issues, missing elements), backlink insights (competitor backlink sources and your authority gap), content gaps, search intent, and prioritized recommendations. Under the hood it is a single agentic LLM with google_search, fetch_page_content, and crawl_webpage tools, capped at 20 iterations. This is the flow you run when you are stuck on page 3 and need to know what changed.
GSC Performance Reporter — automated Google Search Console reporting (flow id 03c28424-d47c-4d64-a667-761da61b6e8b). The GSC reporter costs 8 credits and runs in 1 to 2 minutes. You pass a site URL and a date range. The flow returns a markdown SEO report plus typed arrays for top queries, top pages, quick wins, low-hanging fruit, and recommendations — essentially an automated alternative to most "best seo reporting tools" your team is paying a monthly fee for. Currently this runs against the founder's own Google Search Console connection via Evaligo's connectionId mechanism. Phase 3 (in progress) self-hosts the Google OAuth so any customer can connect their own GSC property and we feed raw rows into a rewired Evaligo flow that bypasses the connectionId. That is the last piece before the SEO engine is fully self-service.
The opinionated playbook ClientCues runs by default
We do not ship the six flows as six disconnected buttons. The seo_playbook engine is an opinionated default sequence we recommend for every new organization. Here is the five-step playbook:
Step 1: Page Auditor on the customer's domain (5 credits). This is the baseline diagnostic. It tells you what is broken before you optimize anything.
Step 2: Backlink Finder on the customer's domain (12 credits). Backlinks are the foundation. You need to know where the link opportunities are before you write content.
Step 3: Keyword Insights on each tracked keyword (15 credits per keyword). This is the competitive gap analysis. For every keyword you care about, you need to know why your competitors rank better and what SERP features they own.
Step 4: SERP Analyzer on each tracked keyword (12 credits per keyword). Once you know the gap, you need to understand the content patterns. The SERP analyzer gives you title formats, word count targets, common topics, and content angles.
Step 5: Content Brief on the top 1 keyword (20 credits). The brief is the deliverable. You take the insights from steps 3 and 4 and turn them into a full content outline with heading structure, internal links, and LSI keywords.
A playbook has a status lifecycle (draft, running, paused, done) and a current_step_idx so the orchestrator can resume after the credit cap kicks in. Customers can reorder steps, drop steps, or change the inputs before clicking "Run playbook". The cadences are configurable. Diagnostic flows run weekly by default. The backlink finder runs monthly. The content brief is on-demand. All of this is driven from one config dict and one background runner. No manual cron per flow.
The playbook is the default because most teams do not know which flow to run first. We built the sequence based on how we run SEO internally. You diagnose, you find backlink opportunities, you analyze the competitive gap per keyword, you extract SERP patterns, you generate the brief. That order works.
Credits, not subscriptions: how we make AI cost transparent
Every Evaligo call is wrapped with the @with_credit_check decorator. Before the call, the decorator checks three things: the org's lifetime credits_cap (default 100 for new signups), the global GLOBAL_MONTHLY_EVALIGO_CREDITS platform ceiling (default 10000 per month, env-overridable), and an is_test_account bypass for internal QA orgs.
On success the decorator writes a credit_ledger row with flow_type, credits_charged, duration_ms, evaligo_job_id, and a sliced input_summary. On block it writes the row with credits_charged=0 and status=blocked. Customers see a per-org usage gauge plus a 402-driven "Request beta upgrade" modal. No surprise bills. No opaque pricing.
The single source of truth for flow costs is EVALIGO_FLOW_COSTS in evaligo_credit_costs.py. One constant, one env var per flow for tuning, one place to audit when GPT-5.x prices move. When the model vendor changes pricing, we change one number and redeploy. The ledger gives us exact per-customer, per-flow cost data. We know which flows are expensive and which are cheap. We can optimize the expensive ones.
The self-rotating recommendation loop that keeps the content fresh
The recommendation system that makes ClientCues content look fresh week after week is the marketing comparison picker. This is the agent that decides what we write about next. It runs every Sunday at 06:00 UTC. Here is the full eight-step pipeline:
1. Build a blacklist from every CompetitorComparison we have already published. We never repeat a subject. The blacklist is a set of apex domains. If we wrote about Mixpanel last month, Mixpanel is blacklisted.
2. Call the Evaligo pick-next-comparison-company flow (flow id f230c300-7395-4c6b-a952-41e7948d9dbc) with the blacklist plus a category hint. The flow runs live web searches across TechCrunch, Hacker News, Product Hunt, and funding-news feeds. It dedupes against the blacklist and returns ONE candidate: name, apex domain, category, why_now (1 to 3 sentences citing recent evidence), suggested_angle, expected_competitors_hint, and confidence (0 to 1). If confidence is below 0.5 we skip the week instead of publishing a thin post.
3. HEAD-validate the picked domain. If it returns a 404, we add it to the blacklist and retry the picker once or twice. No broken links in production.
4. Run the Evaligo competitor-discovery flow on the picked domain. This returns 2 distinct competitors. The discovery flow is the same agentic competitor finder we documented in an earlier post on multi-node agentic flows.
5. Ensure a recent deep-scan exists for the subject plus 2 competitors. We reuse scans if they are within REUSE_DEEP_SCAN_DAYS (30 days). A deep scan is a full website crawl plus feature extraction plus sentiment analysis. Three deep scans means we have the raw data for a comparison.
6. Run the v2 LinkedIn-tuned comparison flow. This flow takes all three deep scans and produces a TL;DR, winners-by-dimension, side-by-side table, and a LinkedIn-ready hook. The comparison flow is tuned for B2B buyers, not generic feature lists.
7. Sanitize the output. We strip em and en dashes, force generated_at to today, and validate the schema. No formatting bugs in production.
8. Auto-generate an OG image and publish. The new CompetitorComparison row appears on /competitors/compare/ and is picked up by the next sitemap build. The content is live within minutes.
That is the self-rotating recommendation loop. The picker agent decides what we recommend talking about this week based on live web signals. It is not a static editorial calendar. It is not a human editor. It is an agent that reads this week's news, checks our blacklist, validates the domain, discovers competitors, runs deep scans, generates the comparison, and publishes. The loop runs every Sunday. The content stays fresh because the picker is always looking at this week's news.
Why an AI SEO platform built on multi-agent orchestration beats a single ChatGPT SEO prompt
Most products sold today as "AI SEO tools" or "SEO automation software" are still some variant of ChatGPT SEO: a prompt template, a single model call, and a markdown response. Here is why we chose multi-agent orchestration for our AI SEO platform instead of a single giant prompt:
Each agent has one job and a tiny, debuggable prompt. We can edit the SERP analyzer's title-pattern prompt without breaking the backlink finder. With a giant prompt, every change risks breaking the entire output.
Each agent has its own retry, timeout, and tool budget. The backlink finder's 15-iteration cap is enforced by Evaligo, not by prompt prayer. If the agent hits 15 iterations, it stops. We do not hope the model stops at the right time.
Failures are inspectable. We see exactly which node returned bad data. With a giant prompt we see "the model hallucinated" and nothing else. With a multi-node flow we see "node 3 (htmlTextExtractor) returned empty string on competitor-domain.com/pricing." That is debuggable.
Costs are per-node. We know that the content brief's 50-page crawler is what makes it the 20-credit flow. We can optimize that node without touching the SERP search or the brief generator. With a giant prompt we have no idea which part is expensive.
We can swap models per node. GPT-5 mini for cheap extraction, Sonnet 4.6 for the synthesis step. With a giant prompt you pick one model for everything. With a multi-agent flow you pick the right model for each job.
Parallel execution. The SERP analyzer fetches 10 pages in parallel. A single LLM call cannot do that. The content brief runs a parallel crawler against your site while it analyzes SERP results. That is only possible with multiple agents.
This is the architecture advantage. Multi-agent flows are harder to build, but they are easier to debug, easier to optimize, and cheaper to run at scale. That is why we built six specialist agents instead of one giant SEO prompt.
How this compares to other AI SEO tools, SEO automation software, and competitor analysis tools
It is worth being explicit about where this fits in the existing market, because "AI SEO platform" is a loaded phrase in 2026 and most products sold under that label do something fairly different from what we built.
Versus generic ai seo tools and seo ai tools. The first wave of AI SEO tools is mostly a thin layer over a single ChatGPT call: paste a URL, get a checklist. Useful for a one-off audit, less useful as the source-of-truth for a real SEO program. Our SEO Page Auditor occupies that same surface area for ClientCues, but it runs as one of six coordinated agents, and the recommendations chain into the Content Brief Generator and Keyword Performance Insights flows. Same intent as the ChatGPT-style tools; very different output once you go beyond one audit.
Versus seo automation software like Surfer and Frase. Rules-based SEO automation software is excellent at content optimization against a known SERP: hit the recommended word count, cover the recommended topics, match the recommended density. Our SERP Content Analyzer and Content Brief Generator overlap with that work, but the analysis is generated per run by an agent rather than scored against a static rule set, and the brief is downstream of the keyword competitor diagnosis instead of a separate workflow. If you live inside Surfer today and the rules-based approach is producing wins, this is complementary rather than a replacement.
Versus competitor analysis tools like Crayon, Klue, and ClientCues itself. Crayon and Klue are best-in-class competitor analysis tools at the enterprise tier, and they are deliberately scoped to competitive intelligence rather than SEO. Our Keyword Performance Insights flow is the SEO-shaped slice of competitor analysis: instead of "what is this competitor doing in the market", it answers "why is this competitor ranking ahead of us for this keyword, and what would close the gap". The two views are complementary. ClientCues runs both as one platform, which is why we built this AI SEO platform on top of the same architecture that already powers our competitor research.
The shorthand we use internally: ai seo tools optimize a page; seo automation software optimizes content against a known SERP; competitor analysis tools tell you what competitors are doing in the market; our AI SEO platform stitches all three views into one workflow on per-call credit pricing.
What is next: self-hosted Google Search Console
Phase 3 is in progress. We are building a new Evaligo flow that takes raw GSC rows as input (no internal connectionId), plus ClientCues-owned Google OAuth, a gsc_connection table, token encryption, and a gsc_data_puller service. Once this ships, every customer connects their own Google Search Console in one click and the GSC Performance Reporter runs against their data instead of ours. That is the last piece before the SEO engine is fully self-service.
Try it: run the AI SEO platform on your own site
The AI SEO platform is live at app.clientcues.com/seo. New signups get 100 credits, enough to run the full five-step playbook on one keyword. You see the cost of every flow before you run it. You see your usage in real time. No $30K contract, no sales call, no opaque pricing.
If you want the broader picture first — what competitive intelligence is, where it overlaps with SEO, and how an AI competitor analysis tool fits next to an AI SEO platform — start with our competitive intelligence guide or our AI competitor analysis use case. If you already know what you need, run the playbook. The difference between a multi-agent AI SEO platform and a one-shot ChatGPT wrapper is the architecture, and the only way to see that is to run both side by side on the same domain.
Instantly compare features and user sentiment across your market. Get a competitor snapshot with real feedback and web proof—free.